LLMs have traditionally been self-contained models that accept text input and respond with text. In the last couple of years, we’ve seen multimodal LLMs enter the scene, like GPT-4o, that can accept and respond with other forms of media, such as images and videos.
But in just the past few months, some LLMs have been granted a powerful new ability — to call arbitrary functions — which opens a huge world of possible AI actions. ChatGPT and Ollama both call this ability tools. To enable such tools, you must define the functions in a Python dictionary and fully describe their use and available parameters. The LLM tries to figure out what you’re asking and maps that request to one of the available tools/functions. We then parse the response before calling the actual function.
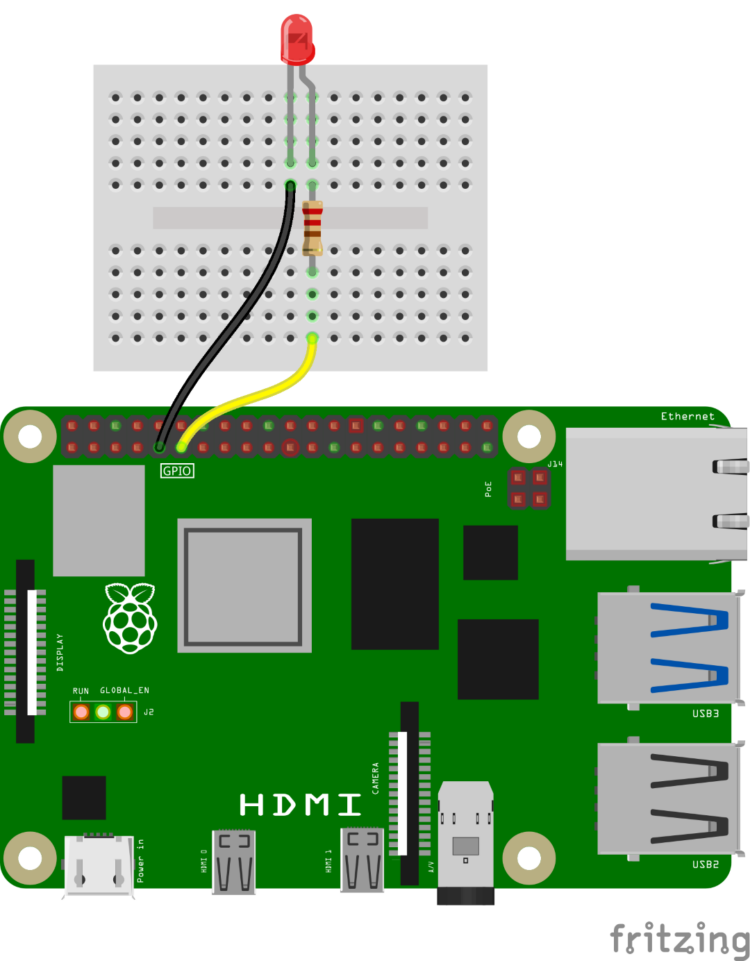
Let’s demonstrate this concept with a simple function that turns an LED on and off. Connect an LED with a limiting resistor to pin GPIO 17 on your Raspberry Pi 5.
Make sure you’re in the venv-ollama virtual environment we configured earlier and install some dependencies:
$ source venv-ollama/bin/activate $ sudo apt update $ sudo apt upgrade $ sudo apt install -y libportaudio2 $ python -m pip install ollama==0.3.3 vosk==0.3.45 sounddevice==0.5.0
You’ll need to download a new LLM model and the Vosk speech-to-text (STT) model:
$ ollama pull allenporter/xlam:1b $ python -c "from vosk import Model; Model(lang='en-us')"
As this example uses speech-to-text to convey information to the LLM, you will need a USB microphone, such as Adafruit 3367. With the microphone connected, run the following command to discover the USB microphone device number:
$ python -c "import sounddevice; print(sounddevice.query_devices())"
You should see an output such as:
0 USB PnP Sound Device: Audio (hw:2,0), ALSA (1 in, 0 out) 1 pulse, ALSA (32 in, 32 out) * 2 default, ALSA (32 in, 32 out)
Note the device number of the USB microphone. In this case, my microphone is device number 0, as given by USB PnP Sound Device. Copy this code to a file named ollama-light-assistant.py on your Raspberry Pi.
You can also download this file directly with the command:
$ wget https://gist.githubusercontent.com/ShawnHymel/16f1228c92ad0eb9d5fbebbfe296ee6a/raw/6161a9cb38d3f3c4388a82e5e6c6c58a150111cc/ollama-light-assistant.py
Open the code and change the AUDIO_INPUT_INDEX value to your USB microphone device number. For example, mine would be:
AUDIO_INPUT_INDEX = 0
Run the code with:
$ python ollama-light-assistant.py
You should see the Vosk STT system boot up and then the script will say “Listening…” At that point, try asking the LLM to “turn the light on.” Because the Pi is not optimized for LLMs, the response could take 30–60 seconds. With some luck, you should see that the led_write function was called, and the LED has turned on!
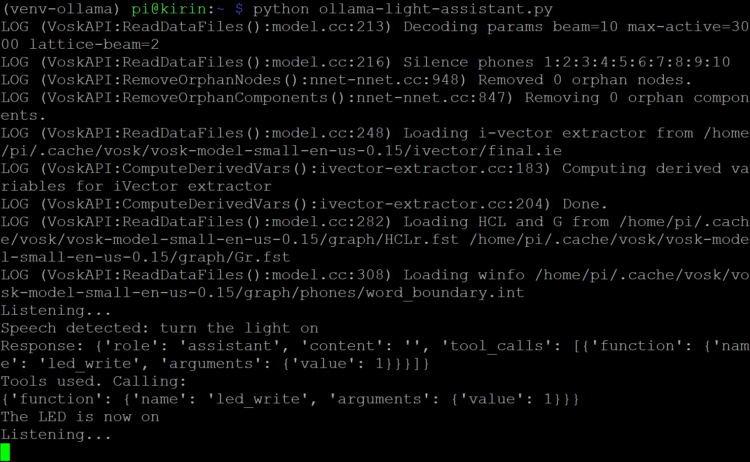
The xLAM model is an open-source LLM developed by the SalesForce AI Research team. It is trained and optimized to understand requests rather than necessarily providing text-based answers to questions. The allenporter version has been modified to work with Ollama tools. The 1-billion-parameter model can run on the Raspberry Pi, but as you probably noticed, it is quite slow and misinterprets requests easily.
For an LLM that better understands requests, I recommend the Llama3.1:8b model. In the command console, download the model with:
$ ollama pull llama3.1:8b
Note that the Llama 3.1:8b model is almost 5 GB. If you’re running out of space on your flash storage, you can remove previous models. For example:
$ ollama rm tinyllama
In the code, change:
MODEL = "allenporter/xlam:1b"
to:
MODEL = "llama3.1:8b"
Run the script again. You’ll notice that the model is less picky about the exact phrasing of the request, but it takes much longer to respond — up to 3 minutes on a Raspberry Pi 5 (8GB RAM).
When you are done, you can exit the virtual environment with the following command:
$ deactivate